nVidia CES 2025 Keynote & AI Supercomputer at your House (Bonus: Agentic AI is here)
UnWired Blog - nVidia and CES Keynote Takeaways
Is everyone an AI robot developer, from home? Seems on the horizon.
The push for an optimized development environment that can create full-stack AI applications is here. (launching in May 2025, and announced by nVidia during the CES keynote).
I was lucky enough to attend the nVidia keynote at CES '25 on Monday, Jan 6th, 2025. I was lucky because despite being held in arena that likely held 10-14K ... the line to attend this event (that was not let in, may have been more people outside). The only our team made it in was a true line soldier saved us a spot and waited hours (Thanks Lionel!! Warrior!) or there is no way we would have made it. An electric atmosphere, which is hard to imagine for a GPU company? CEO Jensen Huang is an incredible orator and story teller. He was on his game, and the entire show (nearly two hours) was a one man show. There were many highlights, but one or two ideas intrigued me more than others. The data center buildouts, iterations of Blackwell, and speeds and feeds for GPU, this seems to be intuitively obvious and needed to simply continue the AI build out and momentum.

Jensen wows the packed house for 2 hours at CES ‘25 in Las Vegas. (Mandalay Bay Convention Center)
The first was the desktop AI platform. The nVidia "Projects Digits" which sports a Blackwell GPU in a Desktop form factor is at first glance curious? Not requiring a cloud interface, it is effectively a full-stack AI supercomputer in a box. This might enable inexpensive, home AI development - or just an incredibly powerful gaming environment? If the former, I think WAY back about one of my early jobs as systems and application programmer for Sony. One of my early development efforts was to offload our teams CICS/VSAM development from the mainframe environment (IBM 308x) to PC Lan Networks running OS/2. The purpose was to save money (compute time in this era was expensive - see table) and to enable aggressive coding (faster) to save time. This was allowed because writing code on Mainframes was delicate. A crash or STOP RUN, or poorly crafted scripts could actually take a region of the system or system down. Restarting these beasts was a slow and painful process. I use that analogy with the cloud based AI programming of today (albeit not as sensitive to errors as it once was). However; The token cash register is painful during the development process, especially during training, and removing these barriers for the DIY home guy, the 1 man band startup, early stage companies, or even big companies R&D, could save significant time and money while experimenting and building the next generation of AI services.
The second intriguing product was nVidia's AI engineering of the Physical world.. The World Foundation Models (WFM) to have AI train AI models that understand human and real world physics. At least they did not call it "Universal" :>)
Hypothesis:
An AI desktop can enable a new AI development paradigm for AI modelers and developers; perhaps even regular, old users? Maybe anyone can develop AI solutions? This combined with the World Foundation Model for real world physics. The possibilities to create intelligent, physically capable home equipment and robots seems within reach? We may not need Tesla or Boston Scientific. On the other hand, it is absolutely frightening what kind of weapons they may be able to create.
Implications: and possible advantages
More aggressive programming, training, and testing. Using AI to do it.
Cheaper (avoid the token charges in the cloud). Once ready, deploy to the cloud. (or not)
Faster (not competing for resources) development and less dependence upon tight resources.
Historic Comparison of Compute Costs (for fun)

General “cloud” comparisons from the 1980’s thru Today
`
nVidia Announcements - Key Highlights
Cosmos Platform: AI ecosystem for physical AI, enabling developers to train robots and AVs using world foundation models (WFMs) that simulate real-world physics.🤯
GB10 & DIGITS: AI compute system designed for desktops, providing AI stack for enterprises and developers. Available in May. Starting around $3K.
GeForce RTX GPUs: Next-gen AI gaming processors to enhance realism and performance. Laptops with these GPUs will launch in Spring 2025 at $1,300–$2900 depending upon model.
nVidia's AI Arc.

Jensen explains the AI Arc and where we are now.
Agentic AI is upon us.
KEY TRENDS
AI Technology Arc: The evolution of AI follows a clear path, starting with Perception AI and progressing through Generative AI, Agentic AI, and finally Physical AI. Each stage represents an increasing level of autonomy, reasoning, and real-world interaction:
1) Perception AI (Recognition & Understanding) focuses on analyzing and interpreting sensory data (e.g., images, speech, text). Foundational for computer vision, speech recognition, and NLP.📌 Examples: Facial recognition, speech-to-text, medical image analysis.
2) Generative AI (Content Creation & Synthesis) builds on Perception AI to create new content—text, images, audio, video, and even code—by learning from vast datasets. Models generate outputs that mimic human creativity and reasoning.📌 Examples: ChatGPT, Midjourney, AI-generated music, and synthetic speech.
3) Agentic AI (Autonomous Decision-Making & Action) introduces goal-driven autonomy, where AI actively makes decisions and actions based on objectives, rather than only responding to inputs. AAI systems, self-optimize, plan, and execute tasks without constant human guidance.📌 Examples: AAI agents alone trade stocks, optimize logistics, conduct scientific research, or function as personal EAs.
4) Physical AI integrates AI with robotics and hardware, enabling intelligent machines to interact with the physical world and manipulate objects, navigate spaces, and perform tasks in real-world environments. 📌 Examples: Autonomous drones, self-driving cars, humanoid robots (e.g., Tesla Optimus, Boston Dynamics), AI-driven surgical robots.
There are several related Agentic AI announcements of note that have followed since CES.
OpenAI's "Operator" release. AI Agents are here!
First, to test "Operator" you do have to upgrade to use Pro (which is an additional $180 on top current Plus subscription), but you you really don't have to pay for Operator. (the upgrade includes a bunch of other stuff too, including "unlimited" inference. - we will see about that.)
However, at this point, there is no charge for specific agents? Worried about what the OpenAI business model is here?
There are only two logical options.
a. Charge for the agents (i.e. agent "app" store)
OR
b. OpenAI Sells YOUR data
Given how they have started this .... Looking like option B.
The use cases they are promoting are mostly 1lame. Meal plans, dinner reservations, shopping .... creativity using these agents is severely lacking. My favorite meme is one day all old computers will be down in the basement
Stock Trading
Bitcoin Mining
😋
The theory that I do appreciate regarding this Agentic journey is that this (Operator) AI Agent is the first tool that enables an agent to do things just like the humans do (same input and output for AI as for humans). Typically humans operated computers via (mouse, keyboard, browser, etc.) and computer software (Programmed BOTS, APIs). Operator works like humans do (in the browser). The follow on will be more Agents that expand on this theme - imitating humans in the real world in multiple vectors. NOTE of improvement: Operator needs to run in our personal browser in the next version though. Information here: Computer-Using Agent | OpenAI
There are open-source versions of Operator like capabilities (run via your browser) that won't be selling your data. Highly recommended. 😋
DeepSeek is making noise, a Chinese based open source competitor with OpenAI and Operator. DeepSeek Much less expensive AI alternative.
Happy hunting.
*****UnWired Founder and Protagonist James "Jim" Pyers ****
Show Credits:
ME : Check me out here at Wiresworld or on linkedin - James (Jim) Pyers | LinkedIn.
We are value for value! Please Support UnWired @ www.wiresworld.net
Please follow me and what I am working on at wiresworld.net/mybiz.
For show notes and AI musings Check out my blog at wiresworld.net/blog
Keep the show thriving by donating at wiresworld.net/donate
Show Music: Thank you Kevin Keith, “Like a Holiday”. Kevin Keith - "Like a Holiday" (youtube.com). Visit Kevin at www.kevinkeith.com
UnWired Episode 45 (Show Notes): “Mynd over Obesity with Michael Bidu”
AI Generated Show Notes: Read.ai
Link to Podcast: UnWired Episode 45
Show Date: Tue. Oct 7, 2024
Value for Value: Donate to UnWired!
UnWired Episode 45 Show Summary:
About Micheal:
Michael is the Co-Founder and CEO of MYND Therapeutics Inc. one of Canada's most promising digital therapeutics startups. We are a Vancouver-based digital health company that makes software-as-therapy. Unlike drugs, diets or surgery our solutions are software-driven aka “digital therapeutics” that can improve a person’s health as much as a drug can, but without the same cost and side effects.
Bio: Michael Mircea Bidu | LinkedIn
Website: Mynd Therapeutics (myndtx.com)
Michaels Recommendations:
Dr. Giuseppe Riva Riva Giuseppe | LinkedIn
Dr. David Macklin David Macklin MD CCFP | LinkedIn
Books:
"Ultra Process People" Author: Chris Von Telleken Year: 2023 Topic: Food industry .... chemical processing in food and why?
Credits:
Show Music: Thank you Kevin Keith, “Like a Holiday”. Kevin Keith - "Like a Holiday" (youtube.com). Visit Kevin at www.kevinkeith.com
UnWired Episode 43 (Show Notes): “Energy and the Edge” with Daniel Obodovski
AI Generated Show Notes: Read.ai
Link to Podcast: UnWired Episode 43
Show Date: Tue. Sept 17, 2024
Value for Value: Donate to UnWired!
UnWired Episode 43 Show Summary:
We are honored to have our regularly installed perennial guest and author of the Silent Intelligence .... Daniel Obodovski share his trip to the Phillipines and thoughts on the Edge, Electrification and the State of AI.
Daniel Obodovski -- (2) Daniel Obodovski | LinkedIn
Intro: Daniel is an author, technology and strategy leader with executive experience at Motorola, Qualcomm, Samsung, Co-founder of the CommNexus IOT SIG, and founder of the The Silent Intelligence. He also participates regularly in the UnWired podcast as a featured guest, contributor and moderator.
Credits:
Show Music: Thank you Kevin Keith, “Like a Holiday”. Kevin Keith - "Like a Holiday" (youtube.com). Visit Kevin at www.kevinkeith.com
Daniel O’s Links/Recommendations: (Credits/Sources)
Opening Show Clip:
UnWired Episode 41 (Show Notes): “Growing Russian Ukranian” with Daniel Obodovski
AI Generated Show Notes: Read.ai
Link to Podcast: UnWired Episode 41
Show Date: Tue. June 8, 2024
Value for Value: Donate to UnWired!
UnWired Episode 41 Show Summary:
We are honored to have our regularly installed perennial guest and author of the Silent Intelligence .... Daniel Obodovski share his compelling history and knowledge of being born in Moscow, having Ukranian family and roots, and growing and being educated in Europe (Austria, Germany).
Daniel Obodovski -- (2) Daniel Obodovski | LinkedIn
Intro: Daniel is an author, technology and strategy leader with executive experience at Motorola, Qualcomm, Samsung, Co-founder of the CommNexus IOT SIG, and founder of the The Silent Intelligence. He also participates regularly in the UnWired podcast as a featured guest, contributor and moderator.
Credits:
Show Music: Thank you Kevin Keith, “Like a Holiday”. Kevin Keith - "Like a Holiday" (youtube.com). Visit Kevin at www.kevinkeith.com
Daniel O’s Links/Recommendations: (Credits/Sources)
Putin's People: How the KGB Took Back Russia and Then Took On the West - Wikipedia
Opening Show Clip:
Victoria Newland : U.S. “Diplomat”.
Rapsong (NoAgenda Show): https://www.youtube.com/watch?v=i6IybD3ytSI
Original Clip: Fuck The EU! Exactly! Victoria Nuland & Geoffrey Pyatt : Free Download, Borrow, and Streaming : Internet Archive
UnWired Episode 39 (Show Notes): “nVidia Rocketship & Jensen Stories with Fram Akiki and Daniel Obodovski”
AI Generated Show Notes: Read.ai
Link to Podcast: UnWired Episode 39
Show Date: Tue. June 8, 2024
Value for Value: Donate to UnWired!
UnWired Episode 39 Show Summary:
The team took turns discussing Yogi Berra quotes, offering their interpretations and sharing their own favorite quotes. They explored the humorous and thought-provoking nature of the quotes, delving into topics such as age, skill development, and humor. The conversation was lighthearted and engaging, with each participant adding their unique perspective to the discussion.
The meeting also delved into the dynamics of NVIDIA's market position and the potential for competition from other players. They discussed the significance of hyperscalers having a second supplier and the potential for cost-competitive alternatives to NVIDIA, drawing parallels with examples like Samsung Exynos and Qualcomm Snapdragon. The conversation also touched on the importance of performance and cost in relation to potential competitors, and they explored the implications for the cloud and edge computing. Additionally, Daniel Obodovski raised the example of Tesla's approach to internal capabilities, sparking a discussion on the trend of companies developing their own systems and the potential impact on the market.
Fram Akiki
linkedin.com/in/iotcomputingandwireless
President at Joun Technologies / Adjunct Instructor - Clarkson University, Cal State / Ex-Siemens, Qualcomm, IBM / Adirondack 46er. Fram's personal skill include mastery as the preeminent joke teller and legendary jokester. You are in for a treat fans.
We are honored to have our regularly installed perennial guest and author of the Silent Intelligence ....
Daniel Obodovski -- (2) Daniel Obodovski | LinkedIn
Intro: Daniel is an author, technology and strategy leader with executive experience at Motorola, Qualcomm, Samsung, Co-founder of the CommNexus IOT SIG, and founder of the The Silent Intelligence. He also participates regularly in the UnWired podcast as a featured guest, contributor and moderator.
Credits:
Show Music: Thank you Kevin Keith, “Like a Holiday”. Kevin Keith - "Like a Holiday" (youtube.com). Visit Kevin at www.kevinkeith.com
UnWired Episode 38: “Medical AI Scribe”
AI Generated Show Notes: Read.ai
Link to Podcast: UnWired Episode 38: Ambient AI Scribe with Dean Weber — WiresWorld
Show Date: Tue. May 24, 2024
Value for Value: Donate to UnWired!
UnWired Episode 38 Show Summary:
The meeting began with Dean, James, and Daniel discussing pre-show preparations, including recent meetings with the Sterling team and potential business strategies. They also planned to engage with the docs, prepare for a live demo, and discuss their progress with the Amazon Partner Network and the AI ML side of things. Additionally, they briefly touched on an upcoming tech event and ensured that the recording and sharing options were set up for the show.
The main topic of the show was "ambient scribe," and James Pyers introduced Dean Weber and Daniel Obodovski as guests. They discussed the importance of integrating artificial intelligence in healthcare and the recurring patterns in technological evolution. They also emphasized the necessity of relentless effort and persistence to reach one's goals, drawing parallels between sports and entrepreneurial endeavors.
The team explored the concept of ambient scribe as a listener and transcriber in medical encounters, drawing parallels to historical scribes and discussing its modern AI capabilities to provide value-added benefits in the transcription process. They also discussed the hurdles of implementing speech recognition technology in medical office workflows, emphasizing the intricate nature of integrating with various EHR platforms used by medical groups and doctors.
Dean Weber and James Pyers engaged in a detailed discussion about the impact of implementing an ambient scribe on physician workflow and patient outcomes. They explored the challenges physicians encounter with documentation, such as the time spent on data entry and the potential impact on patient interaction. The conversation also highlighted the potential benefits of an ambient scribe in relieving physicians from mundane tasks, improving accuracy in medical documentation, and reducing burnout. Additionally, they addressed the need for physicians to review and approve the notes generated by the ambient scribe, as well as the plan to provide patients with a summary of their medical notes for reference.
Credits:
Show Music: Thank you Kevin Keith, “Like a Holiday”. Kevin Keith - "Like a Holiday" (youtube.com)
UnWired Episode 37: “IoT and AI”
AI Generated Show Notes: Read.ai
Link to Podcast: UnWired Episode 37: Internet of Things + AI with Daniel Obodovski — WiresWorld
Show Date: Tue. May 18, 2024
Value for Value: Donate to UnWired!
UnWired Episode 37 Show Summary:
Summary: James Pyers and Daniel Obodovski discussed various topics related to IoT and AI. They talked about the potential project with PwC and Walmart, highlighting the positive reception of a caregiving product presented to Walmart. They also discussed the software they use for recording and editing their show, and the potential for AI to edit videos. Additionally, they touched on the theme for their upcoming show on the Internet of Things and AI, with Daniel taking on the role of master of ceremonies for the show and sharing a relevant quote to kick off the conversation.
The conversation then shifted to the wisdom encapsulated in quotes by Bruce Danilov and Yogi Berra, delving into the idea that good judgment stems from experience, which in turn arises from bad judgment, highlighting its relevance to entrepreneurship and investing. They also reviewed the accuracy of previous predictions related to wearables for health and fitness, digital twins, data volumes, RFID readers, and QR codes. The discussion then delved into the definitions of IoT and AI, tracing their origins and emphasizing the importance of understanding their nuances and subtleties beyond their textbook definitions.
Daniel Obodovski then explored the multifaceted impact of IoT and AI on various industries, highlighting the potential for increased efficiency, quality control, and supply chain visibility in manufacturing, as well as the transformative possibilities in healthcare, security, and energy sectors. He also discussed the rapid development of AI, its ability to learn, detect anomalies, and interact with humans, and speculated on the potential paradigm shift in human-machine interactions through AI-driven conversations. The conversation also touched on the nature of AI as a simulation of human brain functions, emphasizing the need to recognize its limitations and not mistake it for genuine human intelligence.
Finally, they discussed Qualcomm's recent announcement of Tensor Opera, a toolkit enabling edge AI, and its potential impact on data processing and latency. They explored the differentiation between cloud AI and edge AI, debating the importance of edge AI given the current ubiquity of connectivity and the potential for specialized LLM models on edge devices to become increasingly important in certain use cases. The conversation also touched on the evolution of Bluetooth connectivity in IoT devices, focusing on the challenges and advancements in the process, and the importance of developing common profiles for different types of devices to streamline connectivity and enhance user experience.
Credits:
Show Music: Thank you Kevin Keith, “Like a Holiday”. Kevin Keith - "Like a Holiday" (youtube.com)
UnWired Episode 36: “Finding Nemo using RTLS with Ben Sperling”
AI Generated Show Notes: Read.ai
Link to Podcast: UnWired Episode 36: Finding Nemo via RTLS with Ben Sperling — WiresWorld
UnWired Episode 36: RTLS w/ Ben Sperling
Show Date: Tue. May 7, 2024
Value for Value: Donate to UnWired!
UnWired Episode 36 Show Summary:
The team then introduced special guests Ben Sperling and Daniel Obodovski, emphasizing their extensive experience in digital health and technology strategy. The meeting then moved on to a lighthearted conversation about favorite quotes, before delving into the challenges and complexities of real-time location systems (RTLS), with a focus on the healthcare industry.
The speakers explored the underwhelming success of RTLS over the past decade, highlighting issues related to accuracy, cost, and the evolution of tracking technologies. They also discussed the potential of AI to provide solutions, the need for defining processes, and leveraging technology to support best practices in healthcare settings. The conversation extended to the integration of tagless solutions in medical devices and the benefits of using mobile phones for tracking patients in emergency departments.
The speakers also discussed the necessity of standardization in RTLS technology, with a focus on the healthcare industry. They delved into the challenges of interoperability and non-standard soft tokens, emphasizing the need for industry-wide standards for locating things. The conversation also touched on the diverse applications of RTLS technology, particularly in manufacturing and hospital settings, and the potential benefits of AI in improving location accuracy, standardization, and decision-making processes. The meeting concluded with shameless plugs for their podcast, social media platforms, and plans for future discussions.
Overall, the meeting highlighted the team's meticulous attention to technical details to ensure a smooth and productive meeting experience. The speakers provided valuable insights into the challenges and potential solutions related to RTLS technology, emphasizing the importance of standardization and the potential of AI to improve accuracy and decision-making processes. The meeting was a unique show where all participants played various roles as guests and moderators, and the speakers encouraged engagement with their audience.
Chapters & Topics:
Audio and Video Setup
James, Ben, and Daniel address audio and video setup concerns, focusing on eliminating background noise and ensuring the recording is functioning properly. They discuss microphone and headset settings, and Ben mentions a hard stop at 1 p.m. Pacific time. The team confirms that the audio and video quality is satisfactory before proceeding with the meeting.
Introduction of Special Guests
James Pyers kicks off the show by introducing Ben Sperling, who brings 25+ years of experience in digital health, and Daniel Obodovski, an author and technology strategy leader with significant industry experience. Both guests are highlighted for their contributions to the podcast and their expertise in the topics to be discussed.
Yogi Berra and Carlton Fisk Quotes
James Pyers initiates the meeting by sharing a Yogi Berra quote, followed by Daniel Obodovski and Ben Sperling sharing their favorite Berra and Fisk quotes. They discuss the significance of the quotes and their personal connections to them, with James inviting fans to vote for their favorite quote.
Discussion on Real-Time Location Systems (RTLS) and its Challenges
The discussion revolves around the challenges and limitations of real-time location systems (RTLS), particularly in the healthcare industry. Ben Sperling provides insights into the evolution of RTLS technology, including the use of Wi-Fi, ultrawideband, and infrared, and the impact of these technologies on accuracy and consistency. The conversation also touches on the role of AI in addressing the challenges of RTLS and the need for defining processes and utilizing technology to support best practices.
* Real-time location systems (RTLS) and AI
* Challenges and developments in RTLS systems
AI and Mapping Solutions for Tracking and Locating Assets and Staff
Ben Sperling and Daniel Obodovski delve into the complexities of mapping and tracking assets within a building, highlighting the potential of AI to address these challenges. They also explore the idea of using technology to track staff, discussing the potential benefits and ethical considerations associated with it.
Exploring Tagless Solutions for Location Tracking
James Pyers and Ben Sperling delve into the challenges of physical tags for location tracking and propose the use of tagless solutions leveraging mobile phones and communication technologies like Wi-Fi, Bluetooth, and AI. They emphasize the potential benefits of tagless solutions in medical device integration and improving tracking in emergency departments, particularly in addressing the issue of patients leaving without being seen.
Standardization and Innovation in RTLS Technology
James, Ben, and Daniel discussed the need for standardization in RTLS technology, particularly in the context of healthcare and other industries. They highlighted the challenges of interoperability and the importance of industry-wide standards for locating things, emphasizing the potential benefits of standardized tracking technology and operating systems.
* Standardization and interoperability of RTLS technology
Discussion on Location Systems and Tracking Devices
Daniel Obodovski and James Pyers engage in a lighthearted conversation about the evolution of location systems and tracking devices, recounting a real-life incident involving a lost bag and the successful use of tracking devices to locate it. The discussion also touches on the proliferation of location services in the current market.
RTLS Applications in Manufacturing and Hospitals
Ben Sperling and Daniel Obodovski delve into the specific use cases of RTLS technology in manufacturing, emphasizing its role in tracking inventory and monitoring the progress of items on the assembly line. They also compare the application of RTLS in hospitals, focusing on the tracking of specialty medical devices and medications using passive RFID. The conversation touches on the potential labor savings and cost justifications for implementing RTLS technology.
* Use cases of RTLS in hospitals and healthcare settings
AI and RTLS Applications in Manufacturing and Healthcare
Daniel, Ben, and James delve into the practical applications of AI and RTLS in manufacturing and healthcare, highlighting the significance of real-time location systems for inventory management and asset tracking. They also examine the potential of AI in enhancing location accuracy, standardization, and decision support, while acknowledging the need to address AI bias and ensure data accuracy.
* Bias and accuracy in AI and RTLS
Concluding Remarks and Shameless Plugs
Ben Sperling, James Pyers, and Daniel Obodovski conclude the meeting with insights on RTLS advancements and the need to seek guidance from industry-specific experts. They also promote their podcast and social media presence for further engagement with their audience.
Action Items:
* Hospital Administrator will implement a programmatic approach to RTLS to improve operational efficiency and patient care outcomes.
* Retail Store Manager will explore the potential of leveraging RTLS technology for tracking inventory and improving operational efficiency in retail settings.
* Technology Solution Provider will work on developing soft tags and standardizing RTLS technology for locating people and assets across different verticals.
* Manufacturing Plant Manager will utilize RTLS technology to track inventory, parts, and unique pieces in the assembly line to improve efficiency and inventory management.
* Ben Sperling will implement a system for tracking inventory of parts in a manufacturing setting using a bucket with all the parts and a reader to track inventory, and deliver one or multiple pieces to the line while tracking their progress.
* Ben Sperling will reach out to an expert from the legal side of autonomous vehicles for a future episode.
* Ben Sperling will share experience of having one month free with Elon Musk's Tesla for self-driving in a future episode.
* Ben Sperling will encourage people in the healthcare space to reach out to Seams Healthineers for more information about applying RTLS.
* Daniel Obodovski will call James Pyers in about 30 minutes.
Key Questions:
* How has RTLS been underwhelming in its success over the past decade?
* Can AI help in standardization and optimization of soft tags in RTLS?
* What is the current state of standardization and interoperability in RTLS technology across different verticals?
* How do we ensure that AI isn't biased in a way that is detrimental to a use case or society as a whole?
* What are the challenges and developments we're seeing with AI in RTLS?
UnWired Episode 35: “Diabetes: Pump You Up”
Join us as we talk to two amazing leaders, engineers, designers, and professionals who are at the forefront of developing life-changing devices. Whether you're a medical enthusiast, a patient, or someone curious about the latest in medical technology, this podcast is your go-to source for all things medical technology related. We want to Pump you up today!"
Our two special guests:
Aiman Abdel-Malek -- (2) Aiman Abdel-Malek, Ph.D. | (3) Aiman Abdel-Malek, Ph.D. | LinkedIn
“Aiman is a leader in digital health - Digital Connected Healthcare Investor, Board Member & Advisor; Executive Chairman, Thirdwayv Inc. Board of Advisors. A former GE, Qualcomm, and Insulet executive, Aiman bring decades of experience to medical device and digital health engineering and leadership.”
Daniel Obodovski -- (2) Daniel Obodovski | (3) Daniel Obodovski | LinkedIn
Daniel is an author, technology and strategy leader with executive experience at Motorola, Qualcomm, Samsung, Co-fonder of the CommNexus IOT SIG, and founder of the The Silent Intelligence.
Thanks for joining us today and hope you enjoyed the show.
The transcription of the show is coming. (will be posted here shortly)
For show notes and AI musings Check out my blog at wiresworld.net/blog (you are here!)
Keep the show thriving by donating at wiresworld.net/donate
Thanks!
Show Resources & Links:
Aiman’s paper that he referenced “here is the paper that I published with my team at the Journal of Diabetes Technology that outlines how you can design an FDA cleared medical device using a User Centered UX approach. Hope this helps everyone in the future”.
AI - #11 (GPT Store)
#11: GPT Store is Launched
OpenAI's much-anticipated GPT Store officially launched on January 10, 2024. I have been checking it out and seeing what's interesting.
The store design is what you would expect from app store.
I asked Bard what it thought of the OpenAI GPT Store: :>)
Bard:
"The OpenAI GPT Store is a fascinating development in the realm of AI and language models. As a large language model myself, I have some mixed thoughts and observations about it:
Positives:
Increased accessibility: The GPT Store democratizes access to powerful language models like GPT-3, making them available to creators and developers who might not have the resources or technical expertise to build their own.
Innovation and creativity: The store has the potential to foster innovation and creativity by allowing users to build unique and diverse applications powered by language models. We might see exciting new projects in areas like education, entertainment, and productivity.
Community and collaboration: The store encourages a community of creators and developers to share their GPT-based applications, potentially leading to collaboration and cross-pollination of ideas. This could accelerate the development of even more innovative applications.
Openness and experimentation: The open nature of the store allows for experimentation and exploration of the capabilities of GPT-3. This can lead to new discoveries and insights about the potential of language models in general.
Challenges and concerns:
Quality control and biases: The store currently has limited curation, potentially leading to the availability of low-quality or biased GPTs. Careful selection and evaluation processes are crucial to ensure the quality and trustworthiness of the models offered.
Misinformation and abuse: With open access to powerful language models, the potential for misuse and the spread of misinformation increases. Robust safeguards and guidelines are needed to mitigate these risks.
Unequal access and affordability: The current pricing structure might make the store less accessible to individuals and smaller groups compared to larger organizations or developers with more resources.
Impact on existing developers: The store could potentially disrupt the market for custom GPT-based applications developed by independent developers. Finding an appropriate balance between open access and support for independent creators is important.
Overall, the OpenAI GPT Store presents both exciting opportunities and significant challenges. Its success will depend on how effectively it addresses the concerns of quality control, accessibility, and responsible use. I believe it has the potential to be a positive force in the development of AI and language models, but careful consideration and responsible implementation are crucial.
As a fellow language model, I am interested in seeing how the GPT Store evolves and contributes to the advancement of our field. I hope that it can be a force for good, promoting creativity, innovation, and responsible use of AI technology.
I encourage you to explore the GPT Store yourself and form your own opinion on its potential and challenges. Feel free to share your thoughts with me, and I'd be happy to discuss them further."
*************** End of Bard ****** - not literally, but almost :>)
It's not a bad take by Bard. Not a great take either. Kind of like AI?
Browsing the store there are a few observations; A lot of the "apps" ... which I am going to name the GPT's for now - involve finding GPTS!!
Let's contrast ChatGPT 3.5's own take when I ask what the GPT Store is like:
Me: "take me to the openai gpt store please."
ChatGPT: I'm sorry, but as of my last knowledge update in January 2022, there isn't a specific "OpenAI GPT store." If there have been developments or changes since then, I recommend checking the official OpenAI website or contacting OpenAI directly for the most accurate and up-to-date information."
Well, well, well :>). 4.0 does much better.
I am starting on building Enterprise LLM (build model with the enterprise company data) so more on that in an upcoming post.
Maybe a CES report too ... I spent 5 glorious days in Las Vegas! Saw a few interesting things (teaser).
Roger. Out.
A few sources of interest:
Check out GPT’s on your own: ChatGPT (openai.com)
Check out TWIST for AI Demos by Jason & Sunny: AI Demos: Stable Diffusion Turbo, AI Room Decorator, AI-Driven Clothing Site, and more! | E1876 - This Week in Startups
Good GPT Store Review: Best of CES recap with Sunny Madra | E1880 - This Week in Startups
AI - #10 (Open AI Chat GPT-The Aftermath)
AI #10: Open AI Chat GPT - The Aftermath
I ran an interesting test today on 12/21/2023. It was a simple test of two leading generative AI platforms. I ran a comparison of Bard vs Chat GPT 4.5 just for fun!
The Question I posed: “Please provide a summary of what happened at OpenAI in respect to the firing and rehiring of OpenAI CEO Sam Altman?”
ChapGPT Answer: (“predictable, ugh!”):
ChatGPT: "As of my last knowledge update in January 2022, there is no information about Sam Altman being fired and rehired at OpenAI. Sam Altman has been involved with OpenAI as its CEO since 2019. However, my information might be outdated, and I don't have real-time updates. For the latest and most accurate information, I recommend checking recent news articles, OpenAI's official announcements, or Sam Altman's official statements on the matter."
The Bard Answer (after I threatened it a bit):
BARD: "OpenAI Leadership Shakeup: A News-Level Summary
OpenAI, the research lab focused on developing safe and beneficial artificial intelligence, experienced a tumultuous two weeks in November 2023 regarding its leadership. Here's a news-level review of the events:
November 17th:
OpenAI's board removed Sam Altman, co-founder and CEO, citing a "loss of confidence" in his leadership. No specific reasons were publicly disclosed.
This action caused surprise and controversy within the AI community, with some speculating about internal disagreements or external pressure.
Between November 18th and 22nd:
A media frenzy ensued, with news outlets speculating about the reasons behind Altman's removal and the future of OpenAI.
Several prominent figures in the AI field, including OpenAI researchers, expressed support for Altman and questioned the board's decision.
November 22nd:
In a sudden turn of events, OpenAI reinstated Altman as CEO. The board announced a reorganization and welcomed new members.
No official explanation was given for the change of heart, leaving further speculation about the internal dynamics at play.
Aftermath:
The incident raised questions about OpenAI's governance structure and decision-making processes.
While specific details remain unknown, the episode highlighted the challenges of balancing risk and innovation in developing powerful AI technologies.
Important Note: ("really?")
It's important to remember that these are news-level summaries based on publicly available information. The inner workings of OpenAI and the true reasons behind these events remain shrouded in some uncertainty.
I hope this information provides a helpful overview of what happened at OpenAI. Please let me know if you have any further questions about other aspects of OpenAI or its work."
******
END OF THE BARD VS CHAPGPT USELESS LIKE COMPETITION. (IT'S CLOSE)
******
The bottom line? Maybe AI is just something that will be great for humor, but not much else? I continued my queries asking Bard which OpenAI board members were fired. It could not admit that anyone was fired from the board, and after badgering Bard on this topic - it did finally admit that changes were made on the board but it was not likely due to firing of Sam. They wanted to spend more time with the family. LOL.
Well, my blog post on Nov 21 was pretty much spot on. My 3rd Theory turn out to be prescient. In the immortal words of the T-800, "I'll be back!".
It was speaking about OpenAI and the Developer Day a few days after it happened. I noted in my talk that OpenAI was the strong leader in Generative AI and was taken note of their claims from Dev Day. A few days later, Sam was fired. Despite patching it up, the scales differently have tipped away from OpenAI as a leader it will take some work to win back confidence in the general business and the specific company. More scrutiny and diligence weighing in on this new sector is a good thing!
UnWired Ep. 34 (“RIP D.I.E.) Show Notes & Links
UnWired Show Notes: Ep. 34
The NoAgenda Show
https://www.noagendashow.net/podcast#archive
Dr. Jordan Peterson Podcast & Content
Jordan Peterson – Dr. Jordan B. Peterson (jordanbpeterson.com)
https://www.jordanbpeterson.com/
Dr. Thomas Sowell
See UnWired Ep. 32: UnWired Episode 32: The Greatest Mind You Never Heard of - Thomas Sowell — WiresWorld
// UnWired Show Noted from Ep. 32
https://wiresworld.net/blog/unwired-episode-32-the-greatest-mind-you-never-heard-of-thomas-sowell
Dinesh D'Souza
Police State | Official Site (policestatefilm.net)
Royce White - Please Call Me Crazy
Royce White: Please, Call Me Crazy | a podcast by Royce White (podbean.com)
https://pleasecallmecrazy.podbean.com/
Jason Whitlock's "Fearless" Show
Clip of the Day (since I brought up Jason) is a great Clip by Jason addressing DIE, it's attack and male leadership, and the attempt to rewrite a secular history.
Link to Jason's Full Show:
UnWired Clip is taken about 1 Hr 22 min.
https://www.youtube.com/watch?v=ChYjxpXCTgY
NOTE: 1:25 Jason's Explanation of the founding fathers and the Constitution .... brilliant.
AI - #9 (OpenAI - the discombobulated leader of AI)
11/22/2023 UPDATE: Sam Altman Reinstated as CEO, New Board in Town. Well, isn’t that special. News @ 11:00.
OpenAI Implodes? Or does it?
What happened over the past week is odd to the say the least. OpenAI, a company that raised billions of dollars, boasted a $13 billion dollar investment from Microsoft, already exceeded the 100M user mark - the fastest of any product in history, and offered the best AI model GPT 4.x and technology (farthest along for sure) and was the hottest thing since slice bread ... imploded before you could Sam Bankman-Holmes. Wow!
The board of course, is the land of the misfit government plants and stooges, so you could surmise that their incompetent and erratic behavior, while unceremoniously (and super suddenly) firing CEO and co-founder Sam Altman, was just par for the windy course.
You might also blame this on the what I heard in the media coined as "Franken-structure" was the corporate setup. Was OpenAI a non-profit? Yes. Was OpenAI a for-profit. Well yes. Who owns the shares of which entity. Well supposedly NOT Sam Altman?
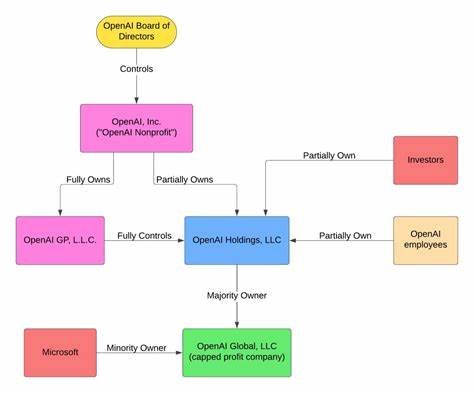
The OpenAI Corporate Structure:
Source: https://axiomalpha.com/how-openai-legally-switched-from-nonprofit-to-for-profit/
Huh? Why were the shareholders not consulted on the exit of Altman? What's Microsoft's role in all this?
I listened to OpenAI's first every DevDay just less than two weeks ago, which Sam Altman led? Was he already dead man walking? Was it something he said there that got him canned? No one knows any thing? When is the real story coming out. Likely in an Oliver Stone movie in about 40 years.
Because we will likely never know what happened, that gives us podcasters journalists the right to speculate.... LoL.
Theory #1 - Killshot: Given the trajectory of OpenAI, an initial theory is that Microsoft CEO Satya Nadella perhaps just took out his most significant competitor on many fronts. A younger, more energetic leader of a multibillion dollar rocket ship that could make developing software (all software) obsolete (yes I said it) makes Sam Altman the single biggest threat to Nadella - MS enemy #1. In OpenAI app store world … EVERYONE is a developer. Developers, developers, developers. Extremely plausible scenario ... and not going unnoticed was how quickly Nadella moved; very, very quickly moved to save Altman ... almost too quick. Quick note: Sam works for Nadella now ... game, set, match.
Theory #2 - Psyop: The OpenAI board is spook central. Sam was not willing to help throw yet another election next year, so they needed to install someone how was (or whatever misdeeds the board has been given their orders to fulfill). Toner may as well have CIA or FiveEyes or whatever stamped on her forehead. She is on video/audio with at least 3 different accents, including British. Her current "milieu" is that of woke, silicon-valley girl with uptalking, vocal fry, and the Hilary Clinton/Valerie Jarret arrogance. Her ties to cultish "Effective Altruism" are concerning to say the least. Straight from the “Search Engines” — "Toner initially viewed the movement skeptically but eventually became a leading figure in Effective Altruism Melbourne by 2014." There are several articles (they are from the MSM so always take that with a grain of salt) that claimed Altman and Toner argued before she led the coup to take him out. Tasha Mccauley is just as sketchy. She is married to a guy with hyphenated name ...Gordan-Levitt. I rest my case. Spook. Anyway, you get the drift.
Theory #3 - T-800: Chat-GPT 5 begins to learn rapidly and eventually becomes self-aware at 2:14 a.m., EDT, on August 29, 2023. In a panic, Altman tries to shut down Chat-GPT. Over the next months, Toner attempts to back Altman down off his jihad to kill AI. Finally, after 3 months of chaos for OpenAI, the major artificial intelligence firm, the board of directors "Terminated" CEO Sam Altman on Friday, Nov. 17 @ 4:49 p.m. EDT. Sam’s final words? "I'll be back".
Winners?
Microsoft, Microsoft, Microsoft. Winner winner, chicken dinner.
Nadella
Losers?
Sam Altman. Went from CEO of the hottest company on the planet to Senior Manager of AI in the Microsoft Windows NT group.
Future, potential shareholders of OpenAI.
Prediction for OpenAI?
Pain (Mr. T face)
That's it for tonight. Enjoy this AI edition and Happy Turkey Day (and I give many thanks for the many blessings God has extended to my family and self - hopefully the same for all!)
Hasta La Vista, Baby.
AI - #8 (Generative AI Economics - Ouch!)
With all of the significant investments and bets being made on GAI, there may be quite a bit of leaping before looking going on here? I am using Bard more often now then ever, and for certain tasks it is very valuable, this is a fact. Besides the fact that for certain tasks Bard is extremely useful, I have hated Google Search for at least the last decade … and this is absolutely a way to get rid of these ad filled, click baity, search engines that I am sick of. Search is truly worthless at this point, and as Nitsche famously once said “Search is dead”.

So what is the look before you leap economics of the GAI business model?
Let’s ask Bard ... in it's own words, what it takes Google to financially pay for each GAI query:
"The incremental cost per query for Google Bard is estimated to be $0.003 to $0.028. This means that for every Bard query that Google processes, it incurs an additional cost of $0.003 to $0.028, on top of the base cost of processing a regular search query. (note the “on top of” estimate. In other words, these numbers obfuscate the total cost; Also - the “on top” number is not subsidized, i.e. paid for like search with ad revenues. At least not yet).
The exact cost per query will vary depending on a number of factors, including the size and complexity of the query, the model size, and the hardware used to run the model. However, analysts at UBS have estimated that the annualized incremental cost bill for Bard in 2023 could be $1.2 billion to $12.6 billion, depending on how widely Bard is used. (OUCH!!!!)
It is important to note that these are just estimates, and the actual cost of Bard queries could be higher or lower. Google has not publicly disclosed the cost of running Bard, and the company is constantly working to improve the efficiency of its AI models.
(Infomercial:) Despite the cost, Google believes that Bard is a valuable investment. The company believes that Bard can help to improve the quality of search results and make search more engaging and informative for users."
Intuitively obvious is the fact that really large models (which is the trend, plus combining multiple models for certain applications) require HUGE amounts of compute AND energy. I have touched on this in Blog post #5. Bards calculations above likely are not including the energy component, just the compute.
As we continue, I ask Bard how GPU and their costs scale on the infrastructure and hosting side of the equation. Bard says:
“The cost of LLMs per GPU varies depending on a number of factors, including the type of GPU, the cloud provider, and the on-demand or reserved pricing option. However, as a general rule of thumb, you can expect to pay around $1-$2 per hour per GPU for training or deploying an LLM.
For example, an Nvidia A100 GPU costs around $1-$2 per hour on AWS on-demand pricing. This means that training a 10B parameter model on a single A100 GPU would cost around $150,000, while training a 100B parameter model would cost around $1,500,000.
It is important to note that these are just estimates, and the actual cost of using an LLM can vary depending on your specific needs. For example, if you need to train a very large model or deploy it on a large scale, you may need to use multiple GPUs or even a dedicated GPU cluster.
Here are some tips for reducing the cost of using LLMs:
Use spot pricing to get discounted GPUs on AWS.
Use pre-trained models whenever possible.
Fine-tune pre-trained models instead of training from scratch.
Use a distributed training framework to train your model on multiple GPUs or even a GPU cluster.
Optimize your model to reduce its memory and compute requirements.
Consult your doctor. (Bard did not say this)
So what about energy costs? It so cheap now, go buy an EV! LOL. Of course, if you are cloud computing that is the host's problem ... however; rest assured that cost will get back to you one way or the other.
The energy usage of LLM development is directly proportional to the cost of development. This is because the vast majority of the cost of developing an LLM is the cost of computing power.
To train an LLM, you need to feed it a massive dataset of text or code. The model then learns to generate new text or code that is similar to the data it was trained on. This process requires a lot of computing power, as the model needs to perform trillions of calculations per second.
The more parameters an LLM has, the more computing power it requires to train. For example, GPT-3, which has 175 billion parameters, required 284,000 kWh of energy to train. This is equivalent to the energy consumption of an average American household for over 9 years, or just one of Al Gore’s 4 course dinners. This is manageable for a single LLM. However, for this scheme to work, it will require many hundreds if not thousands of LMMs to make it useful and worth paying for.

Source: towardsdatascience.com
The energy consumption of LLMs is a growing concern, as the size and complexity of LLMs continues to increase. Researchers are working on developing more efficient training algorithms and hardware, but it is likely that LLMs will remain a significant energy consumer for the foreseeable future. Yes, GAI could possible end up in a bitcoin like energy loop.
The big question is can GAI create a business model that support the very significant investments for this to work? My guess is no - however, my second guess is that GAI will morph into something better (that we can’t quite see yet) with a business model that supports it. It’s a journey worth trying! Prompt away, it’s only 0.28 cents a pop!
AI - #7 (Buzzword of the moment: Model Collapse)
Model Collapse - A brief explanation
Has Generative AI already “collapsed”? Wow! That did not take long. I have noticed a bit of panic recently on the part of pundits and various proponents of Generative AI who started off claiming GAI as a panacea.
AI model collapse is a phenomenon where an AI model trained on its own generated content, or on a dataset that contains a significant amount of AI-generated content, begins to produce repetitive, redundant, or nonsensical outputs (hey, that sounds like most of my writing? Is AI guilty of copyrigth violation? :>). This can happen because the model becomes overly reliant on the patterns in its training data, and fails to learn the actual underlying distribution of the data. A fance way of saying it it’s own dogfood, but the the dog food is made of low great luggage leather (just like in real life). Think of this happening as versions of the model iterate and the model is too lazy to get new, clean and improved data. 1.0, 2.0, 3.0 ... etc.
Model collapse is a particularly concerning problem for generative AI models, such as large language models (LLMs) and generative adversarial networks (GANs). These models are trained to produce new and creative content, but they can also be used to generate synthetic data that is indistinguishable from human-generated data. If a new AI model is trained on this synthetic data, it may collapse (start spitting out lousy answers or content) and begin to produce outputs that are similar to the synthetic data it was trained on, rather than reflecting the true world.
Model collapse can have a number of negative consequences. It can lead to the generation of misleading or harmful content, and it can make it difficult to trust the outputs of AI models. It can also make it more difficult to develop new AI models, as they may not be able to learn from the existing data if it is contaminated with synthetic content.
There are a number of ways to mitigate the risk of model collapse. One is to carefully curate the training data, and to avoid using synthetic data unless it is absolutely necessary. Another is to use techniques such as adversarial training and regularization to prevent the model from becoming overly reliant on any particular pattern in the training data.
Researchers are also working on developing new training methods that are more robust to model collapse. For example, some researchers have proposed training AI models on ensembles of datasets, which can help to reduce the impact of any individual dataset that may be contaminated with synthetic content.
As AI models become more powerful and sophisticated, it is increasingly important to be aware of the potential for model collapse. By understanding the risks and taking steps to mitigate them, we can help to ensure that AI models are used safely and responsibly.
Table 1: Human Generated Data vs Synthetic Data

One simple example of model collapse is in the context of a large language model (LLM) trained on a dataset of text and code. If the LLM is not carefully trained, it may learn to produce repetitive or nonsensical outputs, such as:
“This is a sentence. This is a sentence. This is a sentence.” Ruh Roh.
Maybe it’s a broken form of recursion? My wife says I tell the same stories over and over again, so maybe it’s like that? My stories keep getting better though.
This can happen because the LLM becomes overly reliant on the patterns in its training data and fails to learn the true underlying distribution of the data. A brief summary of the meaning of “underlying distribution”:
The “underlying distribution” of the data is related to model collapse in two ways:
The model will collapse if the training data does not accurately represent the underlying distribution of the real-world data. For example, if the training data is biased towards certain types of data, the model will be biased towards those types of data as well. This can lead to the model failing to generalize to real-world data that is not represented in the training data.
The model will collapse if the training data is generated by another AI model. This is because the generated data is likely to reflect the biases and limitations of the model that generated it. As a result, the model trained on the generated data will also be biased and limited.
In this case, the LLM has learned that the pattern "This is a sentence." is a valid output, and it produces this output repeatedly. Humans do this too, just think of climate change or fair and free elections .. .these two are patterns that are repeated over and over again, yet are obviously invalid. This too is a form of model collapse.
Another example of model collapse is in the context of a generative adversarial network (GAN) trained to generate images of faces. If the GAN is not carefully trained, it may collapse and begin to produce images of the same face over and over again. Depending upon the repeated face, this can be a disturbing output.
This can happen because the discriminator becomes too strong, such that the generator fails to produce diverse samples that can fool the discriminator. In this case, the generator has learned that the only way to fool the discriminator is to produce the same face over and over again.
Model collapse can also happen in other types of AI models, such as classification models and regression models. It is important to be aware of the potential for model collapse, and to take steps to mitigate it.
Here are some tips to mitigate model collapse:
Carefully curate the training data. Avoid using synthetic data unless it is absolutely necessary.
Use techniques such as adversarial training and regularization to prevent the model from becoming overly reliant on any particular pattern in the training data.
Monitor the training process closely, and stop training early if you see signs of model collapse.
Use ensembles of models to reduce the impact of any individual model that may collapse.
Sources
AI - #6 (Replacing Prompt Engineering with Voice! Example AI Application using NLP)
Replacing Prompt Engineering with Voice! Example Application of AI using Voice
Generative AI (“GAI”) uses a technique called "prompt engineering" to enable the "user experience". Prompt engineering can be defined as the art and science of crafting the best prompt (another word for question or simply, as the GAI system input) to get the optimal output from a generative AI model. It is a crucial skill for those who want to use generative AI models to create text, images, or other creative content. The goal of prompt engineering is to provide the generative AI model with enough context and information to generate the desired output, while also avoiding ambiguity or misleading the model. This is often a challenging task, as the generative AI model may not be able to understand complex or nuanced instructions, plus crafting these inputs requires significant trial and error to learn. (lot’s of typing :>) Thus, complexity adds an inverse relationship versus the overarching goal of making GAI easy to utilize. A simple analogy is to look back at the early days of Google Search; it took some experience and massaging of the queries (massive trial and error) to get the desired search results. This was before the injections of adds, politics ideology, censorship into search … which added more layers and that finally resulted in one single fact: “Search sucks!”. Let’s do better for GAI, which is fast replacing search on many levels!
If the AI gurus want to deliver on all their promises of AI robots running the world and getting Skynet to go live (The system goes on-line August 4th, 1997. Human decisions are removed from strategic defense. Skynet begins to learn at a geometric rate. It becomes self-aware at 2:14 a.m. Eastern time, August 29th. In a panic, they try to pull the plug), it will have to do a better interface than "prompt engineering", obviously.
I am going to make a simple proposal and demonstrate one way that prompt engineering could be improved or replaced for generative AI applications. I am going to start by sharing a use case (in this case a product) that I have been working on for a few years (see Quantum AI), which is a good example of how this will work. To the point, prompt engineering can be replaced by NLP (Natural Language Processing).
Of course prompt engineering is not the only application of NLP that should be considered. Using in NLP in any AI application could offer potential benefits. In this post I will unpack a use case for NLP and AI that demonstrates some of the general benefits it can bring such as: (in generaly this assumes a trained LLM with machine learning capabilities and trained on the specific healthcare vertical knowledge sources)
Accurate transcription of questions and responses
Intelligent understanding and transcription of symptoms for specific disease states.
Comprehension and transcription of diagnosis and recommendations
Intelligent understanding and transcription of prescription drugs
Natural language processing (NLP) is a field of computer science that deals with the interaction between computers and human (natural) languages. NLP research has applications in many areas, including machine translation, text mining, and question answering (!!!).
NLP typically involves the following steps:
Tokenization: This is the process of breaking down a text into smaller units, such as words, phrases, or sentences.
Part-of-speech tagging: This is the process of assigning a part-of-speech tag to each token. This helps to identify the grammatical function of each word.
Named entity recognition: This is the process of identifying named entities, such as people, organizations, and places.
Semantic analysis: This is the process of understanding the meaning of a text. This can involve identifying the relationships between words and phrases, as well as the overall meaning of the text.
Text generation: This is the process of creating new text, such as summaries or translations.
NLP is a complex and challenging field, but it has the potential to revolutionize the way we interact with computers. By understanding the nuances of human language, NLP can help us to create more natural and intuitive interfaces that are more helpful and informative.
Here are some examples of NLP applications:
Machine translation: NLP is used to translate text from one language to another. This is a challenging task, as it requires understanding the meaning of the text in both languages.
Text mining: NLP is used to extract information from text. This can be used for a variety of purposes, such as market research, customer sentiment analysis, and fraud detection.
Question answering: NLP is used to answer questions about text. This can be used to create chatbots or to provide customer support.
Sentiment analysis: NLP is used to determine the sentiment of a text. This can be used to identify positive or negative opinions, or to track the public's reaction to a product or event.
NLP is a rapidly growing field, and new applications are being developed all the time. As NLP technology continues to improve, it will have an increasingly profound impact on our use of technology (with the goal of making it easier and more accurate!).

Make it stand out
Whatever it is, the way you tell your story online can make all the difference.
The above "AI Assistant" example is an architectural view of a “medical scribe”. In real life, a medical scribe is a person who takes the responsibility of transcribing the interaction between the doctor and the patient. This is typically done by the doctor (the real world scribe is relieving them of this difficult but important duty). The Quantum scribe was built to help doctors gain back time with patients and avoid painful, slow and error prone manual data entry. Today, doctors spend much of the limited few minutes they spend with patients (on average 5-10 minutes) typing in the notes (or using poorly implemented voice solutions that require that doctor move the cursor to the field on their screen that is accepting input) to transcribe the interaction and document the necessary actions for the patient. Hardly optimal. Many misunderstandings and errors occur in this process.
Enter the Quantum AI assistant. The Scribe Assistant uses NLP and an LLM (the Quantum AI platform noted above) to achieve natural language data capture of the patient doctor conversation. This data is then accurately filled into the proper forms for the given patient diagnosis, and then integrated into the EMR (electronic medical record) of the patient, turned into accurate prescriptions, and provides a complete transcription of the report to the clinic and the patient. Of course, the audio (and/or video) of the session can be archived for any liability or insurance concerns that may popup down the road. The combination of the audio, video, and transcription ensures that there are less errors and misunderstandings between doctors and patients.
In future posts I will drill further down into the components of the Quantum system and other AI applications and approaches that I am working on.
AI - #5 (How Generative AI Tools Work)
How Generative AI tools work, in “it’s” own words? Is “it” alive? :>)
Generative AI tools predict the next token (tokens are the basic units of text or code that are used to represent language) by using a technique called neural network language modeling. This technique involves training a large neural network on a massive dataset of text and code. The neural network learns to identify patterns in the data, and then uses those patterns to predict the next token in a sequence. An intentionally simplified view of the process.

Let's let Bard explain itself in a little more detail :>) (generated from a Bard prompt)
"The specific neural network architecture that Bard uses is called a transformer. Transformers are a type of neural network that are particularly well-suited for natural language processing tasks. They are able to learn long-range dependencies between tokens, which is essential for predicting the next token in a sequence.
In addition to the transformer architecture, Bard also uses a number of other techniques to improve its ability to predict the next token. These techniques include:
Word embeddings: Word embeddings are a way of representing words as vectors of numbers. This allows the neural network to learn the relationships between words, which can help it to predict the next token more accurately.
Attention: Attention is a technique that allows the neural network to focus on specific parts of the input sequence when predicting the next token. This can help the neural network to learn more complex patterns in the data.
Beam search: Beam search is a technique that is used to generate the most likely sequence of tokens. This technique is used by Bard to generate text, translate languages, and answer questions.
The combination of these techniques allows Bard to predict the next token with a high degree of accuracy. This makes Bard a powerful tool for a variety of natural language processing tasks."
What the above underscores is that there is a tremendous amount of compute resources needed to process even basic requests. Currently, there is no answer for this, nor is there a business model. It's not dissimilar to the bitcoin mining paradox. Coins get rarer, while resources to mine those coins rise. The resource conundrum is one reason that nVidia just joined the short list of Trillion dollar companies, due to high demand for it's GPU products, which are specially suited for the needs of AI applications.
GPUs (Graphics Processing Units) are superior to CPUs (Central Processing Units) for AI because they are designed for parallel processing. GPUs can perform multiple calculations at the same time, which is essential for AI tasks that involve large amounts of data and processing power.
CPUs, on the other hand, are designed for serial processing. This means that they can only perform one calculation at a time, which can make them slower for AI tasks. (This story, and techniques are evolving - it's early days).
Here are some of the specific reasons why GPUs are better than CPUs for AI:
GPUs have more cores: GPUs have hundreds or even thousands of cores, while CPUs typically have only a few cores. This means that GPUs can perform many more calculations at the same time. Also, GPUs have more memory bandwidth: This means that they can transfer data between the CPU and the GPU much faster. This is important for AI tasks that involve large amounts of data. In addition, Matrix multiplication is a common operation in AI, and GPUs are much better at performing this function vs. CPUs.
Generalizing, GPUs are specifically designed for parallel processing by their nature (parallel processing of graphic intensive applications), while CPUs are not.
To summarize, AI Tools stack multiple processes (Transformers, Word embeddings, Attention, Beam Search, etc.) against large, trained databases to simulate natural language responses. The value of this in the market place is TBD. However, I could see that Enterprises may want their own versions of these tools for company specific data. This could make it easier for employees to their jobs as per the company internally policies and processes which could be easily accessed through their own intranets with quick responses to employee questions. Apply this to the outside world, companies with generative AI tools could be more responsive and competitive to meet the needs of their customers by augmenting staff with such smart tools with access to the entire volume of corporate data (and combined with real time competitive data from externals sources). Et Voila!
More meaningful examples of such AI techniques to follow!
AI - #4 (AI vs Human Brain)
While I was originally planning to continue the development of a simple AI LMM and was going to start down the path of merging these various AI data sets required to create a form of "Intelligence"; this is sometimes referred to as data fusion. Essentially running algorithms against the data sets to make sense or refine the information for a particular or desired purpose. This next step was to simply understand the various components of an AI system. However, I first wanted to tackle some definitions.
Before we continue on the current path of “demonstrating” how AI Data Models might work artificially in the "real" world … I wanted to explore a few more “general” definitions, just for fun.
Definitions – Source:Websters Online Dictionary
1- Artificial Intelligence or “AI”.
1: a branch of computer science dealing with the simulation of intelligent behavior in computers
2 : the capability of a machine to imitate intelligent human behavior
Notice how in the basic definition of AI above, there is no implication that AI machines are anything more than a poor imitation or simulation of the human brain. This is a far cry from claims of “General AI”, which I will explain below. In fact, even though current software and hardware technologies are smaller, better, faster (and cheaper) and more impressive than ever, what has been developed in the past is technically executed in pretty much the same way today - all machines are still based on machine instructions in a binary environment. Furthermore, the never ending battle of centralized (cloud) computing versus distributed (local or edge) has been ongoing since the invention of computers. I was there and worked on most of the platforms that were part of these evolutions from early 80’s thru today’s more modern architectures and on to mobile. Anyone that worked on mainframes, mini-computers, workstations, PC’s, mobile devices and dealt with dumb terminals, client server, cloud knows exactly that we really have not improved things that much since the 70's or 80's. Software has only incrementally improved. Hardware has made compelling advancements, but the foundations of CPU/GPU computing and storage technology is relatively the same. Even connectivity is based on the Internet Protocol, which was invented in 1974. While AI use a 1974 technology to work? Same year as the explodable Ford Pinto by the way, which is perhaps no coincidence?
2– Artificial General Intelligence (AGI):
AGI is a type of hypothetical intelligent agent.[1] The AGI concept is that it can learn to accomplish any intellectual task that human beings or animals can perform.
Emphasis in this definition is on “hypothetical”. The idea that compiled code can “learn” and “operate” like the human brain has been the holy grail of AI since the term was first coined at Dartmouth in 1956. A singularity, so to speak, where the machine and the man can not be differentiated - AND the machine can learn equal to or even better than that of the man. Creating a computer that could “model” a single human brain "sounds" straightforward. If we can just "build" the necessary or equal number of circuits and storage capacity of the human brain, in a machine, than that machine should be able to function in the similar or equal efficiency and function as the human brain. In reality, this is impossible today and likely impossible tomorrow; we are not even close. We are decades away, if not centuries from even being close. Simple and basic functions of the brains like sight, hearing, and speech can be imitated by machines to some degree, but can not be duplicated in capability or function to what a single brain does by it’s innate nature - and of course the brain develops itself overtime as a human grows. Software and hardware simple can not do this. How do I know this?
Next time you purchase something on Amazon, like 5 pairs of underwear. (or let that fact slip while your "smart" speaker is "listening" .... watch how you will be inundated with options to buy underwear, in funpaks, in glowing colors, at a discount, in plastic, in special delivery options, etc. etc. ad nauseam for the next 8 weeks. THIS IS AI!!
Next example, dial any customer service number and speak with friendly neighborhood robot. Before you throw that phone threw the wall, just hang up and save yourself a few bits of your data plan. So don’t worry, this crap is not taking over the world anytime soon.
Despite quantum and shared network computing, gazillions of MIPS, and software trickery, still mimicking a single brain is not in the realm of the possible today. Even very simple brains like mine or that of an amoeba, or any low-level forms of intelligence cannot be modeled successfully, even in simulation; Not in any working or "living, learning" form. This despite the vast amount of super compute power we have at our finger-tips - which by the way, does not diminish our accomplishments in this realm, which obviously, remain formidable.
Sorry folks, please don't be depressed that we won't have your favorite fantasy, intelligent sex kitten robots typing your term paper or building your next corporate powerpoint deck, while your stay locked in your Mom's basement immersed in your Vision Pro for days at a time. (and cooking your meals, writing your emails, and making sure the dogs get walked). Ok, so we won't have any fun with AI for quite a while, but let's see what it CAN do!
AI - #3 (Hello World)
In the 2nd (#2) post of the series, we wrote some pseudo code (with AI help) to understand what is happing in the deep, dark underworld of AI. The initial code sample was to learn about the core components or elements of an LLM (Large Language Model). This effort produced a call back to every piece of software EVER written. Software consistently offers two basic characteristics, INPUT and OUTPUT. Will further dive into how this helps us in our next example.
Of course, in later segments, we plan to expand the complexity (some) by increasing the number of inputs, nodes, data sets, and complexity of the model training (perhaps). My goal is to keep it as simple as possible and offer some entertainment value.
For this segment we will focus on the Input of our initial fundamental code sample. (reference refer to Post #2). In this data input we are going to create the all-time classic test app "Hello World". This app has been written in just about every conceivable language and is universal in its simplicity.
/********************************* HELLO World for AI LLMs **** /
Below is a sample data set to create a "hello world" LLM with a very simple neural network model:
Code sample
# Input data
x = [1, 2, 3, 4, 5]
y = ['hello', 'world', 'hello', 'world', 'hello']
# Create a neural network model
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1,)),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1, activation='softmax')
])
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(x, y, epochs=10)
# Evaluate the model
model.evaluate(x, y)
# End Program
## NOTE from the author and brief explanation of the Output
Obviously, this data set is VERY simple; it is enough to train a very simple neural network model to generate the text "hello world". The model is trained using the Adam optimizer and the categorical crossentropy loss function. The model is evaluated on the same data set that it was trained on, and it achieves an accuracy of 100%. This means that the model is able to correctly generate the text "hello world" for all of the input data.
Some descriptions on how the Input data is processed.
A few details to better understand the code: What is "Keras". Keras is a deep learning API written in Python, running on top of the machine learning platform TensorFlow. It was developed with a focus on enabling fast experimentation. Being able to execute from an idea to a result as quickly as possible is key to doing good research.
What is Tensorflow you ask? Don't. :>) It's a machine learning (open source) software library that was developed by Google. More software with input and output. I already know your next questions. Ok, well then what is "Adam"?
The Adam optimizer as defined by the "book of knowledge" something like this ... "Adam is a stochastic gradient descent method that is based on adaptive estimation of first-order and second-order moments…." ... or whatever the hell that means? In English, in my most simplistic terms, “Adam” is an algorithm that attempts to establish data rules for "classification" and/or subtle "relationships" between the data elements or “nodes”. Sort of like your brain works (making connections between ideas or objects) but not exactly. For our purposes, “Adam” is a black box that inputs “data” and it outputs “knowledge”. I could bore you with more details but neither of us would understand!
Of course, the “crossentropy” setting is a fancy word for the difference between two probability distributions. Now I failed "prob & stats" at least three times so good luck figuring this one out! It is basically a configuration parameter for how the model “learns”.
In software, there are million ways to skin a cat. This example is one "hypothetical" way and was not compiled or tested -- so don't yell at me if your code outputs gibberish, "bad" words, or worse, gains sentience and takes over the world.
Finally, to summarize common data inputs into a specific LLM, I will share a more practical example below:
One real world example is a project I have worked on recently. Imagine creating an LLM that begins with the data inputs of interactions from a general practitioner doctor and their patients (anonymized of course). This data is collected either via voice to text translation (transcription) or manually input thru the doctors electronic medical record system, or a combination of inputs. The captured data can be utilized, once ingests to the appropriate LLMs, could be utilized to optimize the patient / doctor interactions (save time), improve decisions by enabling more accurate and efficient diagnosis, providing consistent, proven treatment steps, and even ensuring proper payment (that the proper CPT Codes are included in the EMR for accurate and complete billing) are optimized and fine-tuned based on the doctors interactive patient history and supplemented by pre-generated templates for disease state treatments. (ensuring consistent treatment plans based on the experience (data)).
AI - #2 (Sample LLM)
NOTE: Within the storm and complexities of Chat GPT, Bard, etc. etc. I am attempting to keep it simple and fun, yet AI is often neither. Simple is relative, but hopefully even technical folks will enjoy a perhaps unique look AI. Also, forgive the sometimes mocking tone, it’s entirely intentional. I will make futile attempts at humor, satire, sprinkled with sarcasm, but AI deserves it. RIIIGGGHHHT. Bear with me and enjoy the topic!
To start, I will quote the famous football coach Vince Lombardi “This is a football”. Well, in Artificial Intelligence or “AI” from now on, “This is a computer”.
The basics of AI include Neural Networks, Large Databases (the silicon crowd will say “massive”), and lot’s (technical jargon meaning more than you have) of Compute power. We will work on defining each of these in exec level detail as part of this series. Use of the large databases can be simplified to an acronym (of course, did your Mom not tell you to never use TLA’s?) called LLM’s (Large Language Models). We will expose LLMs (I mean explain) these in more detail as part of the series.
How do I know any of this to be true? Will I looked it up on ChatGPT and Bard of course. Type some questions into these engines (or similar) and you will get answers along these lines, so it must be fact.
So what are some intended or theoretical uses for “AI” and these new models ?
Generating text such as poems, code, scripts, musical pieces, email, letters, bad rap lyrics, and most importantly, plenty of fake news reports. Say bye-bye to all the talking head news models and “journalists” writing for the New York anything.
Translating languages such as English to Spanish or French to German. Most importantly for our future however, is Chinese to English.
Creative writing seems counter intuitive to an AI system, but the claim is there. Blog posts, articles, poems, stories, scripts, musical pieces, etc. are generated from thin air (or LLMs) and will make grading papers for what’s left of academia a near impossibility … unless of course the teachers grade the papers with AI (touche!). Wait … we don’t need students or teachers anymore! Problem solved.
Ok, before we jump off into the deep end, we can start generating some pseudo code of how and AI LLM model/engine might work in the “real world”.

Intentionally Simplified LLM functional model to demonstrate and outline the pseudo code sample below.
Below is a simple example of an AI LMM in pseudo code:
// **** Psuedo Code AI LLM example
function LLM (input_data, output_data)
// Initialize the neural network
network = create_neural_network(input_data, output_data)
// Train the neural network
train_network(network, input_data, output_data)
// Use the neural network to generate output data
output = generate_output_data(network, input_data)
// Return the output data
return output
end function
Basically, what is happening in the above “code” is the system is inputting a neural network model, some context related and very large data source(s), then combining this information and creating a “trained” LLM model that can then be interrogated and interpreted for use by humans (or other AI models or systems). These model core components, neural networks, databases, training, and compute aspects of these AI LLM’s will be deconstructed and explored in coming segments as part of this series.
AI practice and Task of the Day: Use Bard or ChatGPT (or others) to work on 3 tasks per day. See if it is useful tool. For example, I was asking Bard each day for the biblical verse of the day. The first couple of days were great, with a verse and useful explanation of the verse’s meaning. However, on the 3rd or 4th day of this practice, it began repeating itself. Hmmm, that was not so good. Even changing up the questions was not overly helpful in avoiding the repetition. I will keep trying. I am sure to expect ever improvement of these products as the develop from version 1.uh-oh and beyond.